为什么要控制Googlebot的抓取速度?


温馨提示:注册会员付费购买资源可永久免费下载更新版本

有时候很高兴看到谷歌几乎瞬间抓取了你的网站。但这对于大多数网站来说并不是必须的,因为内容可能一天更新一次,甚至间隔更长。当内容没有更新的时候,搜索引擎爬虫或者机器人继续在网站上寻找更新是没有意义的。
在本文中,我们将了解为什么要控制Googlebot,以及如何控制Googlebot和其他搜索引擎爬虫的爬行速度。
为什么要控制Googlebot的抓取速度?
当你有多个站点或者更大的站点时,搜索引擎机器人的持续抓取会对服务器性能产生不利影响。所以,控制抓取你网站的机器人的抓取速度是很有必要的,而Googlebot在很多情况下是你首先要控制的。
搜索引擎机器人和真实用户都会使用你的服务器资源。
高爬网率将导致高CPU利用率,最终可能导致更多额外资源的开销。在共享托管环境中,您的主机可能会停止服务,以保护同一服务器上托管的其他站点。
当Googlebot抓取网站时,网站上的真实用户可能会感觉很慢。尤其是当你拥有一个电子商务网站时,你必须控制Googlebot和其他经常爬行的机器人。
如果你的网站很小,流量有限,你可能看不出机器人有什么问题。当你有多个每天吸引成千上万访问者的网站时,你会注意到由于爬虫的活跃,CPU的使用量猛增。当CPU使用率很高时,您可能会收到来自托管公司的警告消息,或者您的帐户将被暂停,要求您采取必要的措施。
如何监控Googlebot?
有两种方法可以监控Googlebot的抓取活动。一个是从你的谷歌搜索控制台检查,另一个是从你的主机账户监控。
登录到您的谷歌搜索控制台帐户,导航到设置,然后抓取>抓取统计数据>打开报告。在这里,您可以查看Googlebot在过去90天内的活动。您将看到三个图表——每天抓取的页面,每天下载的千字节数,以及下载页面花费的时间(以毫秒为单位)。这些图表会让你全面了解Googlebot在你的网站上做了什么。
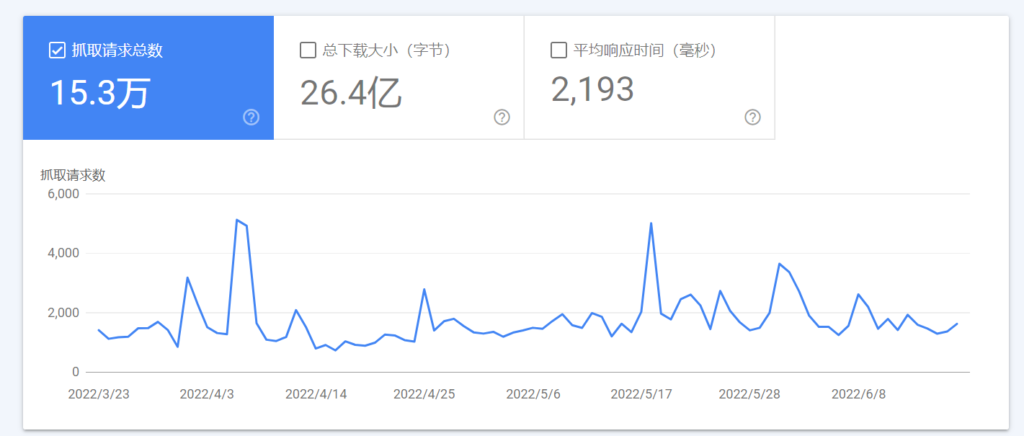
Googlebot在你的网站上捕捉数据统计。
第二种也是最有效的方法是通过您的主机帐户监控服务器上的活动。登录您的主机帐户,找到一个统计报告工具。在这种情况下,我们使用几乎所有共享主机服务提供商(如Bluehost、SiteGround等)提供的Awstats。)进行解释。
打开Awstats应用程序并选择您的站点以查看统计数据。查看“机器人/蜘蛛访客”部分中最活跃的机器人列表。

Awstats的监控机器人
还可以使用WordFence等插件来监控实时流量和Googlebot活动。
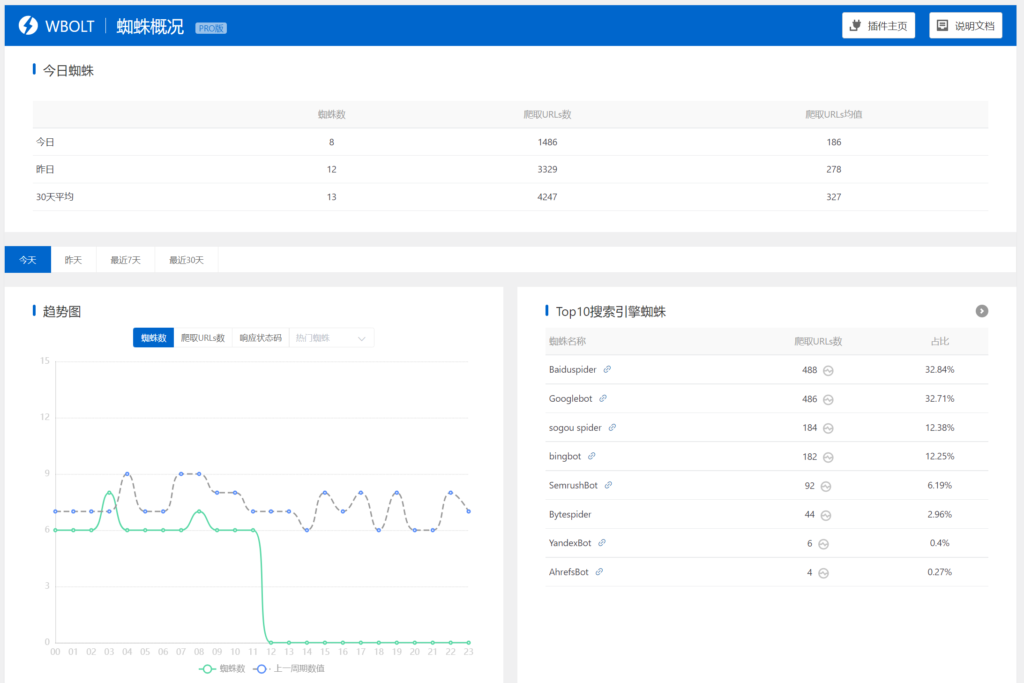
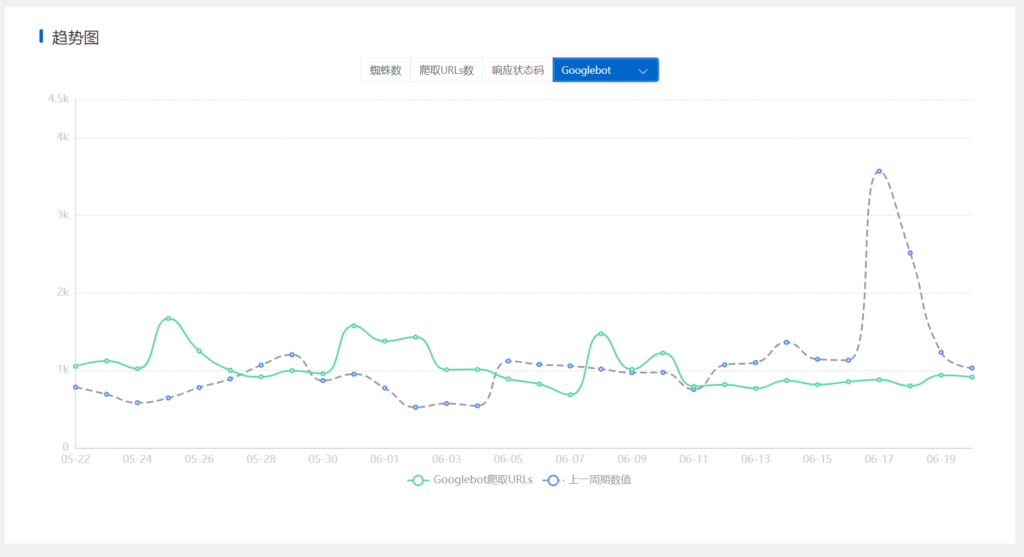
当然,我们的蜘蛛分析插件也可以实现爬虫统计和行为分析。安装启用插件后,当然是统计一段时间的数据。点击Spider Analysis > Spider Profile,然后选择最近30天,在趋势图下面的菜单中选择Googlebot,查看最近30天Googlebot抓取的URL数量。
如何控制Googlebot的抓取速度?
当你注意到Googlebot正在抓取你的网站,消耗了大量的带宽时,就该控制抓取速度了。一些主机公司通过在robots.txt文件中添加条目来自动控制抓取延迟。你可以从谷歌搜索控制台手动控制Googlebot的抓取速度。登录你的搜索控制台账号后,打开你的资源的抓取速度设置页面,选择你需要设置Google Spider抓取速度的网站。
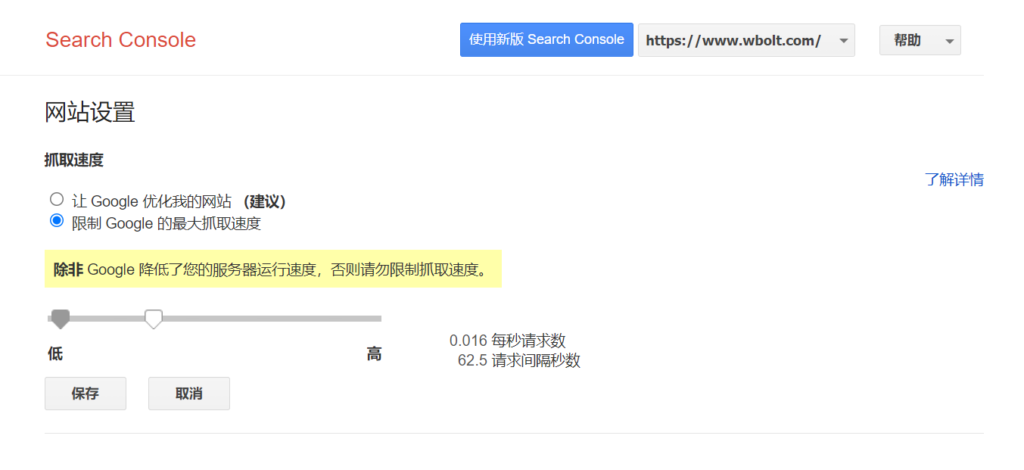
访问Google搜索控制台中的爬网控制设置
你会在“抓取速度”部分看到两个选项。
谷歌机器人抓取速度控制
让谷歌优化我的网站(推荐)
限制谷歌的最大抓取速度
选择第二个单选按钮,将进度条向下拖动到所需的速率。这将设置每秒的请求数和抓取请求之间的秒数。
注意:除非谷歌的抓取导致你的网站性能严重下降,否则完全没有必要修改谷歌爬虫的抓取速度。谷歌在控制这一块做得非常好。
的新抓取速度设置有效期为90天,到期后会自动重置为第一选项“让谷歌优化我的网站”。
冰在哪里?
类似Googlebot,也可以在Bing站长工具下限制Bingbot。登录到您的帐户后,导航到“配置>爬网控制”,您可以进行相关设置。
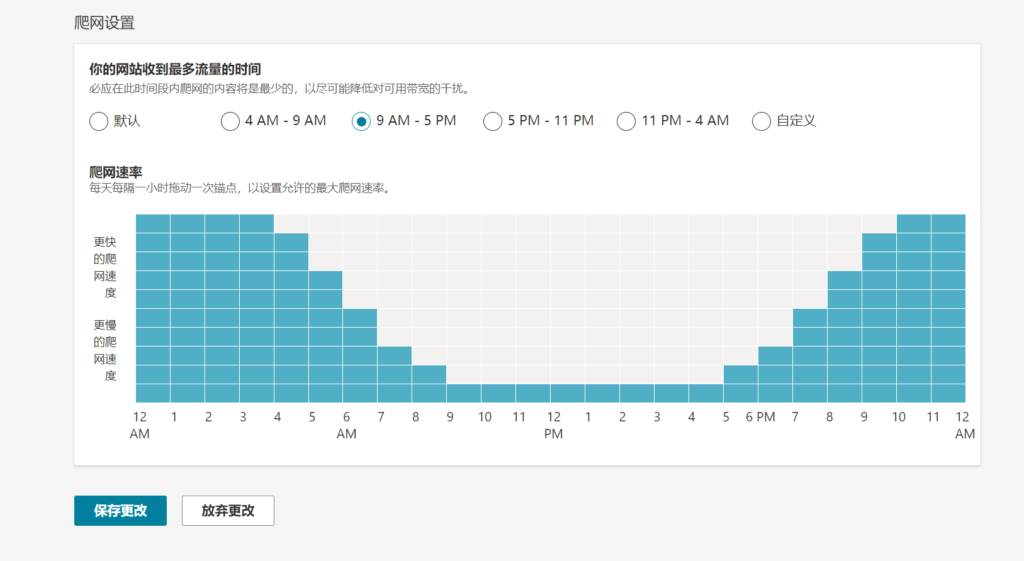
Bing网站管理员工具中的抓取控件
通过选择图表上的蓝框来调整抓取速度。
其他搜索引擎爬虫
除了Google和Bing,还有很多其他的机器人可以抓取你的网站。您可以使用通用的。htaccess命令阻止所有其他机器人。将下面的代码添加到您的。htaccess文件来阻止除谷歌,必应,MSN,MSR,Yandex和Twitter以外的所有机器人。所有其他机器人将被重定向到本地主机IP地址127.0.0.1。
#Disable bad botsRewriteEngine OnRewriteCond %{HTTP_USER_AGENT} ^$ [OR]RewriteCond %{HTTP_USER_AGENT} (bot|crawl|robot)RewriteCond %{HTTP_USER_AGENT} !(bing|Google|msn|MSR|Twitter|Yandex) [NC]RewriteRule ^/?.*$ “http://127.0.0.1” [R,L]
还可以通过IP地址屏蔽一些蜘蛛的访问和爬行拒绝。
总结
为了将主机服务器的CPU利用率保持在允许的范围内,有必要监控网站上的爬虫活动。我们已经解释了一些方法,还有许多其他方法可以阻止坏机器人。这也是一个好主意,与你的主机讨论,并确保你做正确的事情,只阻止坏机器人。
最后,边肖的建议是,例如,国内站长,来自搜索引擎的蜘蛛,如谷歌、百度、必应和搜狗等。,在不必要的情况下尽量不要干涉。有一些未知的蜘蛛爬虫,我们要尽量把它们挡在外面,避免浪费服务器资源(这个可以通过蜘蛛统计分析插件智能拦截)。
声明:
1,本站分享的资源来源于用户上传或网络分享,如有侵权请联系站长。
2,本站软件分享目的仅供大家学习和交流,请不要用于商业用途,下载后请于24小时后删除。
3,如果你也有好的建站资源,可以投稿到本站。
4,本站提供的所有资源不包含技术服务请大家谅解!
5,如有链接无法下载,请联系站长!
6,特别声明:仅供参考学习,不提供技术支持,建议购买正版!如果发布资源侵犯了您的利益请留言告知!
创网站长资源网 » 为什么要控制Googlebot的抓取速度?