详细了解Robots.txt,以及如何用标准化的方式编写。


温馨提示:注册会员付费购买资源可永久免费下载更新版本

关于Robots.txt,相信大部分WordPress站长都不会陌生。一个标准化的Robots.txt对于WordPress网站的SEO优化是必不可少的。这个文件主要用来告诉搜索引擎爬虫哪些页面可以抓取,哪些页面不可以。
我们曾经在《WordPress网站Robots.txt如何编写和优化》中详细介绍过Robots.txt。但是,今天这篇文章将更加详细,便于站长解读和更好地利用Robots.txt文件。
Robots.txt是网站中最简单的文件,但也是最容易出错的。仅仅一个字符错误就可能影响你的SEO结果,阻碍搜索引擎抓取你网站的有效内容。
robots.txt文件的配置错误经常发生,即使是经验丰富的SEO人员。
在本教程中,您将学习:
Robots.txt文件是什么?
Robots.txt是什么样子的?
Robots.txt中的用户代理和指令
什么时候需要robots.txt文件?
如何找到您的robots.txt文件
如何构建robots.txt文件
机器人最佳实践. txt
Robots.txt文件示例
如何检测robots.txt文件中的问题
Robots.txt文件是什么?
Robots.txt文件用来告诉搜索引擎网站上哪些页面可以抓取,哪些页面不可以抓取。
首先,它列出了你想从搜索引擎(如谷歌)中排除的所有内容。也可以告诉一些搜索引擎(非Google)如何抓取网站内容。
重要提示
大部分搜索引擎都会遵守规则,并没有打破规则的习惯。换句话说,少数搜索引擎会忽略这些规则。
谷歌不是那种难以驾驭的搜索引擎。它们遵守robots.txt文件中的声明。
我们只知道有些搜索引擎完全忽略了它。
Robots.txt是什么样子的?
以下是Robots.txt文件的基本格式:
Sitemap: [URL location of sitemap]User-agent: [bot identifier][directive 1][directive 2][directive …]User-agent: [another bot identifier][directive 1][directive 2][directive …]
如果你以前没有看过这些内容,你可能会觉得很难。但实际上,它的语法非常简单。简而言之,您可以通过在文件中指定用户代理和指令来为搜索引擎蜘蛛分配爬行规则。
让我们详细讨论这两个组件。
用户代理(用户代理)
每个搜索引擎都有一个特定的用户代理。您可以在robots.txt文件中将爬网规则分配给不同的用户代理。用户代理大概有一百多种(其实你只要安装Spider Analyser插件就可以很容易知道哪些蜘蛛访问抓取了你的网站。),下面是一些对SEO有用的用户代理:
谷歌:谷歌机器人
谷歌图片:谷歌机器人图片
冰:冰机器人
雅虎:咕嘟
百度:Baiduspider
达克达克戈:达克达克博特
提示:robots.txt中的所有用户代理都严格区分大小写。
您还可以使用通配符(*)一次为所有用户代理制定规则。
例如,假设您想要阻止除Google之外的搜索引擎蜘蛛,下面是如何做的:
User-agent: *Disallow: /User-agent: GooglebotAllow: /
你要知道在robots.txt文件中,你可以指定无数个用户代理。也就是说,无论何时指定新的用户代理,它都是独立的。换句话说,如果您一个接一个地为另一个用户代理制定规则,那么第一个用户代理的规则不适用于第二个或第三个用户代理。
一个例外是,如果您为同一个用户代理制定了多个规则,这些规则将一起执行。
重要提示
蜘蛛只会遵循准确指示详细用户代理的指令。所以顶部的robots.txt文件只会排除Google Spider以外的搜索引擎爬虫(以及其他类型的Google Spider)。谷歌会忽略一些不太具体的用户代理声明。
指令(说明)
说明是指您希望用户代理遵循的规则。
当前支持的命令
以下是Google目前支持的指令及其用法。
不允许指令
使用此指令指定搜索引擎不访问特定路径中的文件和页面。例如,如果您想阻止所有搜索引擎访问您的博客及其所有帖子,robots.txt文件如下所示:
User-agent: *Disallow: /blog
提示:如果在disallow命令后没有给出详细的路径,搜索引擎会忽略它。
允许指令
使用此指令指定搜索引擎需要访问特定路径中的文件和页面,即使该路径被disallow指令阻止。如果您阻止除特定文章之外的所有文章页面,那么robots.txt应该如下所示:
User-agent: *Disallow: /blogAllow: /blog/allowed-post
在这个例子中,搜索引擎可以访问:/blog/allowed-post。但是它不能访问:
/blog/another-post/blog/that-another-post/blog/download-me . pdf
谷歌和必应都支持这一指令。
小费。像disallow指令一样,如果您没有在allow指令之后声明路径,那么搜索引擎将会忽略它。
规则冲突的描述
除非您非常小心,否则在某些情况下,disallow指令会与allow指令冲突。在以下示例中,我们阻止了对该页面/博客/的访问,并打开了该页面/博客。
User-agent: *Disallow: /blog/Allow: /blog
在本例中,URL /blog/post-title/似乎被阻止并允许。那到底是哪一个?
对于Google和Bing,它们将遵循具有更长指令字符的指令,在本例中是disallow指令。
不允许:/博客/ (6个字符)允许:/博客(5个字符)
如果deny指令与allow指令的长度相同,则限制较小的指令将胜出,即allow指令。
小费。在这里,可以抓取/blog(不带斜杠后缀)。
严格来说,这只适用于Google和bing搜索引擎。其他搜索引擎会遵循第一条指令,即disallow指令。
网站地图说明
使用此命令来标记站点地图的位置。如果你不熟悉网站地图,它通常包含所有你需要被搜索引擎抓取和索引的页面链接。
以下是使用Sitemap指令的robots.txt文件:
Sitemap: https://www.domain.com/sitemap.xmlUser-agent: *Disallow: /blog/Allow: /blog/post-title/
robots.txt中指明sitemap指令有多重要?如果您已经向Google提交了网站地图,这一步是可选的。但是其他搜索引擎,比如Bing,可以准确的告诉它你的网站地图在哪里,所以这一步还是很有必要的。
请注意,您不需要为不同的代理重复标记sitemap命令。所以最好的办法就是把sitemap指令写在robots.txt的开头或者结尾,像下面这样:
Sitemap: https://www.domain.com/sitemap.xmlUser-agent: GooglebotDisallow: /blog/Allow: /blog/post-title/User-agent: BingbotDisallow: /services/
支持Google sitemap命令,Ask,Bing,Yahoo搜索引擎都支持。
小费。您可以在robots.txt中使用多个站点地图指令
不支持的指令
以下是Google不再支持的一些指令——部分是因为技术原因,它们从未得到支持。
爬行延迟指令
您可以使用此命令指定之前的捕获间隔(以秒为单位)。例如,如果您希望Google Spider在每次爬网后等待5秒钟,那么您需要将爬网延迟指令设置为5:
User-agent: GooglebotCrawl-delay: 5
Google不再支持这个指令,但是Bing和Yandex仍然支持。
也就是说,在设置这个指令时,你需要小心,尤其是如果你有一个大的网站。如果将Crawl-delay命令设置为5,蜘蛛一天只能爬行17,280个URL。如果你有几百万的页面,这个抓取量是很小的。相反,如果你是一个小网站,它可以帮你节省带宽。
Noindex指令
这一指令从未得到谷歌的支持。但直到最近,人们还认为谷歌有一些“代码来处理不受支持和未发布的规则(如noindex)”。因此,如果你想阻止谷歌索引你所有的博客页面,那么你可以使用以下指令:
User-agent: GooglebotNoindex: /blog/
同时,2019年9月1日,谷歌明确表示不支持这一指令。如果你想从搜索引擎中排除一个页面,使用meta robots标签或者x-robots HTTP header命令。
Nofollow指令
这一指令从未得到谷歌的官方支持。它被用来阻止搜索引擎跟踪一个链接或一个特殊的路径。例如,如果你想阻止谷歌跟踪所有博客链接,你可以这样设置指令:
User-agent: GooglebotNofollow: /blog/
谷歌在2019年9月1日声明不会支持这一指令。如果你想阻止搜索引擎跟踪页面上的所有链接,那么你应该使用meta robots标签或者x-robots HTTP header命令。如果你想指定一个Google不会跟随的链接,那么你可以给这个特定的链接添加rel=”nofollow “参数。
需要Robots.txt文件吗?
对于一些网站来说,robots.txt存在与否其实并不重要,尤其是小网站。
说了这么多,也没什么好理由不要。它可以让您对搜索引擎访问网站的规则进行额外的控制,因此它可以帮助您:
防止对重复页面进行爬网;
保持网站在某个阶段的私密性(比如建立网站原型的时候);
防止对内部搜索页面进行爬网;
防止服务器过载;
防止谷歌浪费抓取预算;
阻止一些图片、视频和其他资源显示在谷歌搜索结果中。
请注意,虽然Google通常不会在robots.txt中对被屏蔽的网页进行索引,但也不能保证使用robots.txt文件就能100%将其排除在搜索结果之外。
谷歌表示,如果内容从另一个地方获得链接,它可能仍会呈现在搜索结果中。
如何找到你的robots.txt文件?
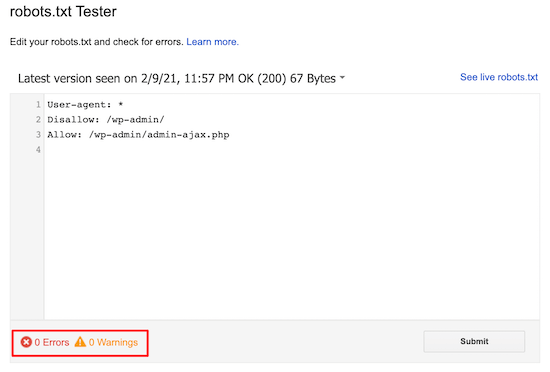
如果您的网站已经有robots.txt文件,那么您可以通过domain.com/robots.txt.的链接访问它。如果您看到如下信息,这是您的robots.txt文件:


如何构建robots.txt文件?
如果你没有robots.txt文件,做一个很容易。你只需要打一个空的. txt文件(记事本文件),按照要求填写说明即可。例如,如果您希望搜索引擎不对您的/admin/目录进行爬网,您可以将其设置如下:
User-agent: *Disallow: /admin/
只要满意就可以继续添加指令,然后将文件保存为“robots.txt”。
除此之外,你还可以使用robots.txt生成工具来制作它,比如智能SEO工具插件:
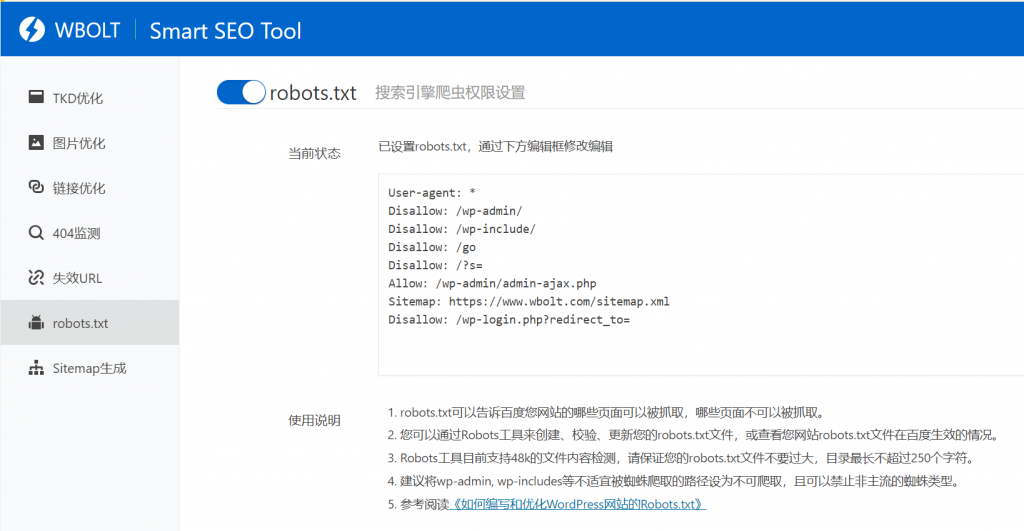
使用这样的工具的好处是更容易编辑和管理。当然,为了避免命令语法错误,建议任何工具生成的robots.txt都要用搜索引擎站长的工具检查,比如百度资源管理平台。
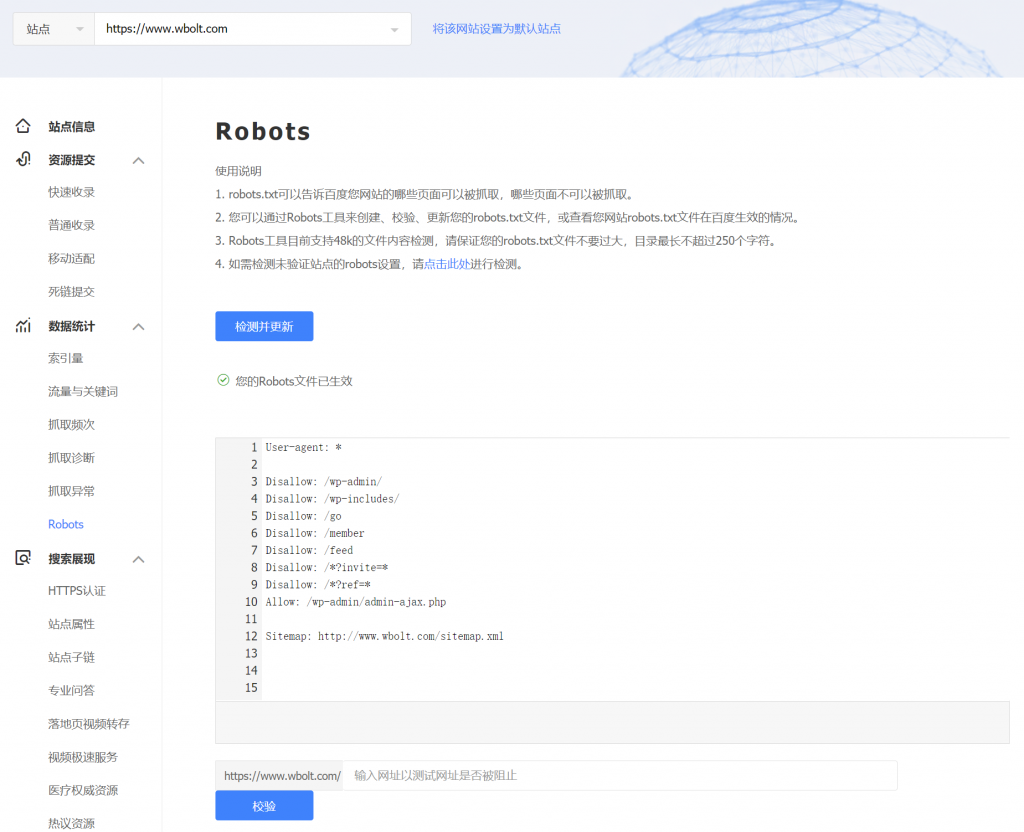
这一点非常重要,因为一个小小的语法错误就可能导致灾难性的后果。还是小心点好,不要犯大错。
robots.txt文件放在哪里?
将robots.txt文件放在相应域名/子域名的根文件夹中。例如,如果你的网站使用domain.com,robots.txt可以通过domain.com/robots.txt.访问
如果你想控制二级域名的访问限制,比如blog.domain.com,那么它的robots.txt需要通过blog.domain.com/robots.txt.访问
机器人最佳实践. txt
请记住以下提示,以避免不必要的错误:
每个新指令都需要一个新行。
每条指令需要一个新行。否则,搜索引擎会误解:
错误示例:
User-agent: * Disallow: /directory/ Disallow: /another-directory/
标准示例:
User-agent: * Disallow: /directory/ Disallow: /another-directory/
使用通配符来简化指令。
您不仅可以使用通配符(*)将指令应用于所有用户代理,还可以在声明指令时匹配相同的URL。例如,如果您想阻止搜索引擎访问您网站上的参数化产品类别URL,您可以像这样列出它们:
User-agent: * Disallow: /products/t-shirts?Disallow: /products/hoodies?Disallow: /products/jackets?…
但并不简洁。您可以使用通配符并将其缩写如下:
User-agent: * Disallow: /products/*?
这个例子是为了阻止所有搜索引擎用户抓取/product/目录,所有包含问号(?).也就是说,所有带参数的产品链接都被屏蔽了。
使用美元符号($)来标记以特定字符结尾的URL。
在指令末尾添加“$”。例如,如果您想要阻止所有以结尾的链接。pdf,那么你的可以这样设置你的robots.txt:
User-agent: * Disallow: /*.pdf$
在这个例子中,搜索引擎不能抓取任何以结尾的链接。pdf,也就是说搜索引擎爬不到/file.pdf,但是搜索引擎可以爬这个/file.pdf?因为它没有以“,”结尾。pdf”。
同一个用户代理只声明一次。
如果多次声明同一个用户代理,虽然Google没有异议,但仍然可以一起实现。比如像下面这个…
User-agent: GooglebotDisallow: /a/User-agent: Googlebot Disallow: /b/
… Google Spider不会抓取这两个目录中的任何一个。
说了这么多,最好只声明一次,因为不会造成混乱。换句话说,保持简单明了可以让你不犯致命的错误。
使用精确的说明来避免意外错误。
如果不使用精准的指令,很可能会导致SEO出现致命错误。假设您现在有一个多语言网站,并且正在运行/de/子目录的德语版本。
因为还没完成,所以你想暂时阻止搜索引擎抓取这个目录的内容。
下面的robots.txt文件可以阻止搜索引擎抓取此目录和下面的所有内容:
User-agent: *Disallow: /de
但是,同时也阻止了搜索引擎抓取所有以/de开头的内容..
例如:
/设计师服装/
/delivery-info . html
/de cache-mode/t恤衫/
/绝对不公开. pdf
在这种情况下,解决方法也很简单,只需在后面加一条斜线:
User-agent: *Disallow: /de/
使用注释为开发人员提供指导。
使用注释功能,你可以向开发者解释你的robots.txt指令的用途——可能是你未来的自己。如果需要使用注释,只需以(#)开头:
# This instructs Bing not to crawl our site.User-agent: BingbotDisallow: /
蜘蛛会忽略所有以(#)开头的指令。
对不同的子域使用不同的robots.txt文件。
Robots.txt只在当前子域生效。如果需要控制不同的子域抓取规则,那么就需要分别设置不同的robots.txt文件。
例如,你的网站在domain.com运行,你的博客在blog.domain.com运行。然后你需要有两个robots.txt文件。一个在主站根目录,一个在博客站根目录。
Robots.txt文件示例
下面举几个robots.txt文件的例子。这些主要是给你一些启发。但如果恰好符合你的需求,请复制粘贴成记事本文档,另存为“robots.txt”,然后上传到对应的根目录。
允许所有蜘蛛访问。
User-agent: * Disallow: /
提示。如果没有在指令后声明URL,将会使指令变得多余。换句话说,搜索引擎会忽略它。这就是为什么这里的disallow指令是无效的。搜索引擎仍然可以抓取所有的页面和文件。
不允许蜘蛛来访。
User-agent: *Disallow: /
阻止所有蜘蛛的目录。
User-agent: *Disallow: /folder/
对于所有的蜘蛛,屏蔽一个目录(只保留一个页面)
User-agent: *Disallow: /folder/Allow: /folder/page.html
阻止所有蜘蛛的文件。
User-agent: *Disallow: /this-is-a-file.pdf
阻止所有蜘蛛的所有pdf文件。
User-agent: *Disallow: /*.pdf$
对于谷歌蜘蛛,屏蔽所有带参数的网址
User-agent: GooglebotDisallow: /*?
如何检测robots.txt文件中的问题?
Robots.txt容易出错,需要检测。
要检测与robots.txt相关的问题,只需在搜索控制台(Google Explorer)中查看“覆盖率”报告。以下是一些常见错误,包括它们的含义和解决方法:
您需要检查与页面相关的错误吗?
将特定的URL放入搜索控制台(Google Explorer)的URL检查工具中。如果它被robots.txt阻止,那么它将显示如下:
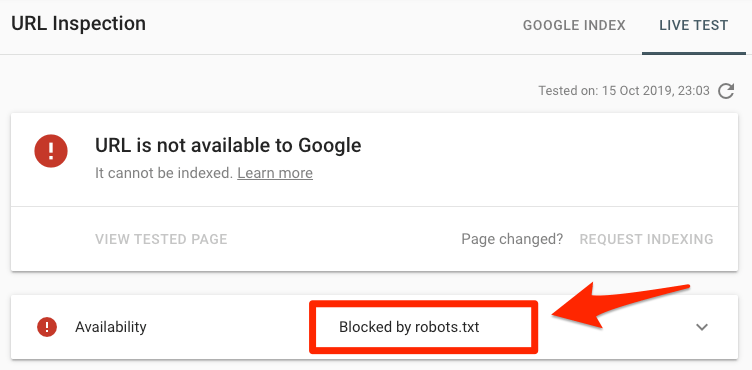
提示:国内站长可以使用百度搜索资源平台提供的相关功能进行检测!
提交的URL被robots.txt阻止
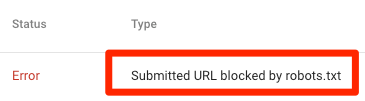
这意味着您提交的站点地图中至少有一个URL被robots.txt阻止
如果你已经正确地创建了你的站点地图,并且它不包含诸如规范化索引(标准标签)、noindexed(指定不被索引)和重定向(跳转)的页面,那么你提交的所有链接不应该被robots.txt阻塞。如果被阻塞,调查受影响的页面,然后相应地调整robots.txt文件,并删除阻塞页面的指令。
可以使用Google的robots.txt检测工具或者百度搜索资源平台的robots文件检测,看看是哪个指令在阻止访问。进行更改时需要小心,因为这很容易影响其他页面和文档。
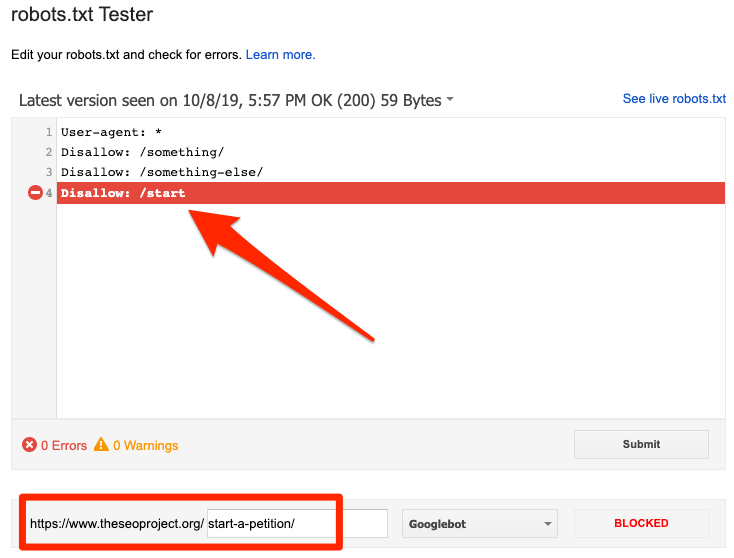
被robots.txt屏蔽了
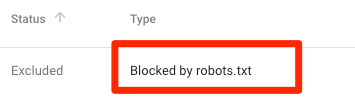
这意味着,目前你的内容被robots.txt屏蔽,但暂时没有被Google索引。
如果这个内容很重要,需要索引,删除robots.txt中阻碍抓取的指令。(同时,你还得注意这个内容是否被index标签标记为非索引。)如果你需要屏蔽的内容同样没有被Google索引,那么你可以去掉屏蔽和抓取的命令,然后用meta robots标签或者x-robots HTTP header命令屏蔽掉——这样才能保证内容不被索引。
小贴士。
如果要从索引中删除页面,必须先删除爬网块。否则,Google将无法抓取页面的noindex标记或HTTP header指令——这只会使搜索引擎保持原始索引状态。
但是索引被robots.txt屏蔽了
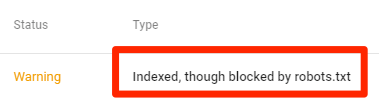
这意味着,尽管一些内容被robots.txt屏蔽,但仍被谷歌编入索引。
同样,如果你想从搜索引擎中删除这些内容,robots.txt也不是最好的选择。移除抓取块,并使用meta robots标签或x-robots HTTP头指令来防止被索引。
如果您不小心阻止了这些内容,并希望它被Google索引,您只需删除robots.txt中阻止索引的指令,这将有助于您的内容在Google中更好地显示。
常见问题
下面的问题是经常被问到的,但是上面的内容没有涉及到。你可以在评论里留下你的问题,我们会根据情况进行更新。
(1)1)robots . txt文件的最大大小是多少?
大约500千字节。
(robots.txt在2)WordPress哪里?
例如:domain.com/robots.txt.
(3)如何在Wordpress中编辑robots.txt?
你可以手动编辑,或者使用Wordpress SEO优化插件。比如像智能SEO工具,它允许你直接在后台编辑robots.txt文件。
如果我通过robots.txt屏蔽非索引页面会有什么影响?
谷歌看不到你的noindex标记,因为它无法抓取这些信息。
最后的想法
Robots.txt是一个简单却强大的我。明智地使用它可以对SEO产生积极的影响。随意使用,可能会造成灾难性的后果。
(via ahrefs.com译者朴成,文章有改动)
声明:
1,本站分享的资源来源于用户上传或网络分享,如有侵权请联系站长。
2,本站软件分享目的仅供大家学习和交流,请不要用于商业用途,下载后请于24小时后删除。
3,如果你也有好的建站资源,可以投稿到本站。
4,本站提供的所有资源不包含技术服务请大家谅解!
5,如有链接无法下载,请联系站长!
6,特别声明:仅供参考学习,不提供技术支持,建议购买正版!如果发布资源侵犯了您的利益请留言告知!
创网站长资源网 » 详细了解Robots.txt,以及如何用标准化的方式编写。